



A boarded-up high street
If I told you that a company’s website traffic fell by 40 per cent in one year, that its userbase had completely crashed and that its revenue went up 17 per cent in the same year, would you believe me?
This is what happened to Stack Overflow, the world’s largest question-and-answer site for software developers. Since 2008, programmers have posted technical problems there, other programmers have answered them for free and the result is an archive of 83 million questions and answersi that became one of the open web’s most valuable public goods. The question-and-answer format was so effective that it generated an entire Stack Exchange ‘cinematic universe’ of spin-offs around topics from theoretical physics to personal finance and theology.
The website recently received a sleek new look, but it is doubtful that anyone has noticed. These days, Stack Overflow feels like a boarded-up high street. Only ghosts amble around those discussion threads. Ghosts and large language models.
These ghosts inspired the trick to Stack Overflow’s profitable survival. The company pivoted towards licensing its human-curated content to the AI companies whose large language models are now scraping its contents.
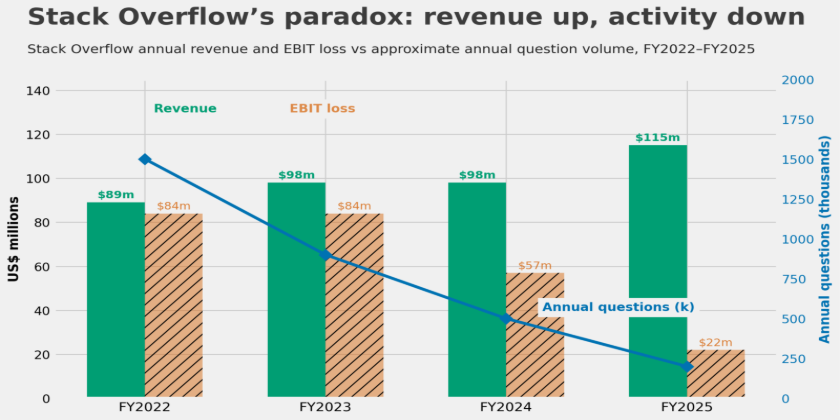
Prosus, which acquired the platform for $1.8 billion in 2021, reported $115 million in revenue for the year to March 2025, driven by API partnerships with OpenAI and Google.ii Monthly questions cratered from over 200,000 in 2014 to 25,000 by December 2024.iii By January 2026, the figure was 2,640.iv In February 2026, Stack Overflow and Cloudflare co-launched a pay-per-crawl system, charging AI bots for access in real time.v Fewer visitors, more money. So far so great, but the archive is finite, and almost nobody is adding to it.
Everyone else is selling
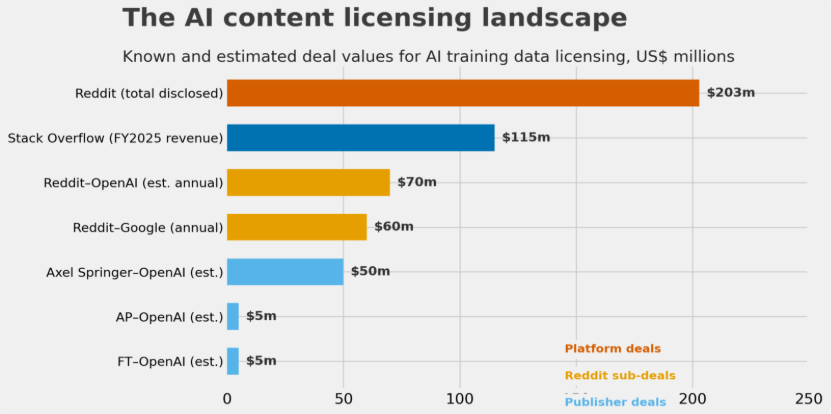
Platforms that spent two decades giving content away for free have discovered that the same content commands a price when fed to a large language model. Reddit disclosed $203 million in data licensing contracts in its February 2024 IPO prospectus, including a deal with Google worth $60 million annually.vi By Q2 2025, AI licensing contributed $35 million in a single quarter, about 10 per cent of Reddit’s total revenue.vii Axel Springer, the Financial Times, Condé Nast and the Associated Press have all signed similar agreements.viii
The reason AI companies find this human-produced content so valuable is that large language models seem to only be trainable on human-produced content. In a 2024 paper in Nature, Shumailov and colleagues showed that AI models trained on outputs generated by other language models lose information.ix A follow-up paper the following year established that even small proportions of machine-generated data in a training set can cause the same harm.x As AI-generated text floods the open web, clean, human-authored training data becomes scarcer and more valuable.
Regulators and protocols
Legislators around the world have not hesitated to introduce new regulations around AI activity. The European Union’s AI Act requires providers of general-purpose AI models to publish summaries of their training data and respect rights-holders’ opt-outs, regardless of where a model was trained. In March 2026, the European Parliament called for a register of every copyrighted work used in AI training.xi Some countries have leaned towards more liberal regimes. Japan permits copyright exceptions for training, and US courts have been moving towards ‘transformative use’ defences.xii
In September 2025, a coalition including Reddit, Yahoo, Medium and Quora launched Really Simple Licensing, or RSL, an open protocol allowing publishers to embed machine-readable licensing terms in their websites. By December, over 1,500 media organisations had endorsed the specification.xiii The protocol supports pay-per-crawl and pay-per-inference models, and the nonprofit RSL Collective functions as a clearing house.
Nevertheless, as of early 2026, no major AI company has signed up.xiv Chiefly because compliance is so hard to measure. In spite of some efforts to create protocols which prevent bots from scraping a webpage without a licence, no one can reliably tell in real time when and who is scraping the content of a particular webpage. Property rights without measurement are unenforceable, and unenforceable property rights are not really property rights at all.
Have you got a licence for that?
The open internet was built on millions of people contributing local knowledge to a decentralised commons. The proposal now is to selectively fence off that commons through property rights enforced by licensing. If data has value, then it should have a price. So the logic goes, but licensing deals are bilateral arrangements between large platforms and a handful of AI labs. In this budding licensing system, things like personal blogs or small academic journals that don’t have negotiation power are either deprived of these property rights or at the very least would linger in a grey area.
Copyright law already gives publishers ownership over their content. The problem with current data licensing models is that this right lacks three things it needs to function as the basis of a market: clear boundaries, low transaction costs and measurable use. Compare a human-authored paragraph on the internet to a farmer’s field. A fence may serve as the field’s visible boundary. If the farmer wants to sell access to his field, both parties can agree on terms because the thing being sold is observable. As far as a written paragraph is concerned, copyright law says the author owns it, but there is no fence, as the content is potentially visible to anyone with a browser. A crawler can copy the text without the author knowing, and once the paragraph enters a training set, it is hard to verify whether or how it was used. The property right exists on paper but lacks the practical machinery that makes property rights tradeable.
Ronald Coase argued that if property rights are well defined and transaction costs are low, private bargaining will produce efficient outcomes regardless of who holds the right initially. By this standard, the data licensing market fails on both conditions. Rights are poorly delineated in practice, and transaction costs are enormous as negotiating a bespoke deal with each AI lab is only feasible for platforms the size of Reddit or Stack Overflow. The result is that large players can afford to negotiate bilateral deals, but everyone else is left out. Personal blogs, small academic journals, and niche forums that lack negotiation power are either deprived of the value of their property rights or linger in a grey area where those rights go unpriced.
RSL is an attempt to lower transaction costs through standardisation, much as commodity exchanges standardised grain contracts in the nineteenth century. But standardisation alone is insufficient if the underlying use remains unmeasurable.
A potential market-based solution
If the problem is measurement, the answer may be to stop measuring inputs and start pricing outputs instead.
Enterprise customers, such as banks deploying AI for compliance or hospitals using it for diagnostics, need to know that a model’s outputs are reliable and legally defensible. What companies want is a guarantee about the product, so a warranty on the AI model’s training provenance gives them that.
Working backwards, we can assemble the following chain of incentives. The AI company wants to offer the warranty because enterprise customers will pay more for warranted models. But it cannot credibly issue its own warranty, for the same reason a car manufacturer cannot inspect its own safety record. An independent intermediary issues the warranty instead, with its capital at risk if a claim is triggered. The intermediary therefore certifies the training data before underwriting, vetting its provenance and authorship. Certified content then commands a higher licensing fee because AI companies need it to obtain warranty coverage. Publishers invest in certification because certified content is worth more money. Each party responds to a price signal from the party immediately downstream.
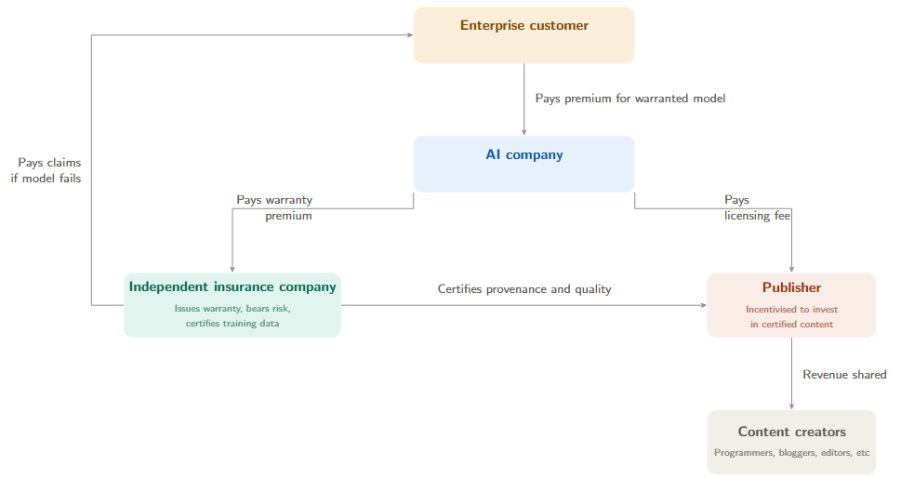
The system brings a number of benefits. First, it enables price discovery across the whole market. Today, Reddit knows what its data is worth because it negotiated a deal with Google. A mid-sized trade journal has no idea, because no good mechanism exists to reveal that price. An insurance system creates one. The intermediary’s certification tiers and the warranty premiums attached to each tier produce a visible schedule of prices.
Second, it delivers consumer protection. Today, an enterprise deploying an AI model has no recourse if the model produces poor output because of bad training data. It may not even know who supplied the data. A warranty creates the missing link. If the model fails, the warranty pays out. The intermediary then can push the cost of failure back to the responsible party. This would bring AI models into the same type of system other industries use today. A car buyer does not directly sue the steel mill that provided materials for the car. If something goes wrong, the car buyer claims on the warranty, and the manufacturer traces the fault.
Third, like all insurance systems, it pools risk. Any single publisher faces unpredictable revenue. An insurance pool absorbs these shocks across many publishers, just as homeowners’ insurance absorbs the cost of a single house fire across many premiums.
Fourth, and most importantly for the long-term health of the open web, it gives platforms a direct financial incentive to pay contributors for new content. Stack Overflow’s archive is finite and ageing. If the certification system rewards fresh, human-authored content above old archives, then Stack Overflow earns more by attracting new contributions than by reselling old ones. Attracting more quality content usually involves paying contributors. Stack Overflow has actually already begun exploring this, but the incentive is currently weak because licensing revenue is all about selling access to existing supply. It’s not hard to imagine that an insurance system would drive higher premia for fresh products in many circumstances.
For solo bloggers and anonymous contributors, a voluntary publisher mutual that pools small contributions and distributes revenue by quality score could complement this system well, with membership voluntary and governance set by the members themselves.
Whether the current licensing gold rush is a sustainable business model or a brief arbitrage opportunity depends on whether property rights in data can be made practical, not just legal. The insurance model suggests they can, by pricing quality at the output rather than tracking every input.
 | A guest post by
|